Clustering with win2k, Cluster Service for Netware, Unix for Server Cluster and Linux TurboCluster Server.
Writing an introductory paragraph about clustering solutions in general will be probably more confusing than clarifying. This is not due to the idea behind clustering, but it's on the conto of the different organizations involved in offering clustering solutions: their own defenitions and the specific benefits as a result of the features of the OS it's running on.The following is a very basic defenition:
providing redundancy (High Availability) and having all together
one type of "entrance door" to which the clients connect to.
Devices are at least two computers, the entrance door is at least
one network connection with one and the same IP address.
The aims of a cluster are the following:
- Providing permanent access to resources on a 24x7 basis
- Scalability
- Better manageability
- Maintenance without downtime
- Speeding up processes through load balancing and parallelization
Microsoft Cluster Service (MSCS) Introduction - Goals - Definitions - Architecture/Management - Other - Future - More info
Introduction
Microsoft's traditional definition of clustering: A cluster is a collection of computer nodes that work in concert to provide a much more powerful system.
Clusters have the advantage that they can grow much larger than the largest single node, they can tolerate node failures and continue to offer service, and they can be built from inexpensive components. Further, the software cluster can scale to many nodes at a single site, and can scale geographically, creating a single "server" that spans multiple locations. Microsoft Cluster Service (MSCS) extends the Windows NT operating system to support high-availability services. The goal is to offer an execution environment where off-the-shelf server applications can continue to operate, even in the presence of node failures. Later versions of MSCS will provide scalability via a node and application management system (with cluster-aware (parallel) applications) that allows applications to scale to hundreds of nodes.
The following figure shows an overview of the components and their relationships in a single system of a Windows NT cluster.
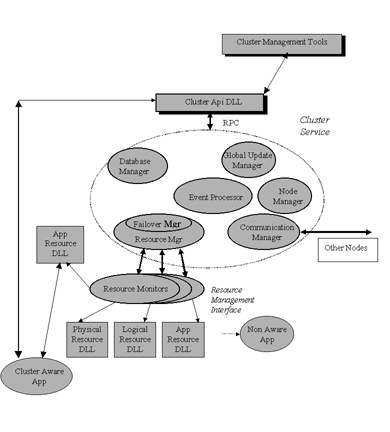
Figure 1. Architecture of MSCS
Cluster Design Goals
MSCS adopts a shared nothing cluster model, where each node within the cluster owns a subset of the cluster resources. Only one node may own a particular resource at a time, although, on a failure, another node may take ownership of the resource. Client requests are automatically routed to the node that owns the resource. The first phase of MSCS had the following goals: commodity, scalability, transparency and relability with the Cluster Service.
Definitions
- A Node is a self-contained Windows NT system that can run an instance of the Cluster Service. Groups of nodes implement a cluster. There are two types of nodes in the cluster: (1) defined nodes are all possible nodes that can be cluster members, and (2) active nodes are the current cluster members. A node is in one of three states: Offline, Online, or Paused.
- A Recource is representing a certain functionality offered at a node. MSCS implements several resource types: physical hardware such as shared SCSI disks and logical items such as disk volumes, IP addresses, NetBios names and SMB server shares. Applications extend this set by implementing logical resources such as web server roots, transaction mangers, Lotus or Exchange mail databases, SQL databases, or SAP applications. A resource has an associated type, which describes the resource, its generic attributes, and the resource's behavior as observed by the Cluster Service.
- The Quorum Resource provides provides an arbitration mechanism to control membership. It also implements persistent storage where the Cluster Service can store the Cluster Configuration Database and change log. The Quorum Resource must be available when the cluster is formed, and whenever the Cluster Configuration Database is changed.
- Resource Dependencies are declared and recorded in a dependency tree. The dependencies between the different resources can't cross the resource group boundaries.
- A Resource Group is the unit of migration (failover). Failover policies are set on a group basis, including the list of preferred owner nodes, the failback window, etc.
- The Cluster Config Database contains all configuration data necessary to start the cluster. The initial node forming the cluster initializes the database from the Quorum Resource, which stores the master copy of the database change logs. The Cluster Service, during the Cluster Form or Join operations, ensures that the replica of the configuration database is correct at each active node. When a node joins the cluster, it contacts an active member to determine the current version of the database and to synchronize its local replica of the configuration database. Updates to the database during the regular operation are applied to the Master copy and to all the replicas using an atomic update protocol similar to Carr's Global Update Protocol.
Cluster Architecture/Management
The management of the components of the cluster is done through the Cluster Service. The following table presents its components and functionality (see also Figure 1.).
| Component | Functionality |
| Event processor | Provides intra-component event delivery service |
| Object manager | A simple object management system for the object collections in the Cluster Service |
| Node manager | Controls the quorum Form and Join process, generates node failure notifications, and manages network and node objects |
| Membership manager | Handles the dynamic cluster membership changes |
| Global Update manager | A distributed atomic update service for the volatile global cluster state variables |
| Database manager | Implements the Cluster Configuration Database |
| Checkpoint manager | Stores the current state of a resource (in general its registry entries) on persistent storage |
| Log manager | Provides structured logging to persistent storage and a light-weight transaction mechanism |
| Resource manager | Controls the configuration and state of resources and resource dependency trees. It monitors active resources to see if they are still online |
| Failover manager | Controls the placement of resource groups at cluster nodes. Responds to configuration changes and failure notifications by migrating resource groups |
| Network manger | Provides inter-node communication among cluster members |
In addition to the Cluster Service, MCSC uses several other support components: The Cluster Network (for the heartbeat management between the nodes), Cluster Disk Driver (for implementing the shared disk mechanism required for the Quorum Resource), Cluster Wide Event Logging and the Time Service (to synchronize the clocks with universal time).
Other
- This cluster concept also comprises Virtual Servers, providing a simple abstraction for applications and administrators. Applications run within a virtual server environment, aka it provides the application with the illusion that it is running on a virtual NT node with virtual services, a virtual registry, and with a virtual name space. When an application migrates to another node, it appears to the application that it restarted at the same virtual NT node.
- Client Access: the mentioned virtual server resource group requires a node name resource (NetBios and DNS), and an IP-address resource. Together, these present consistent naming for the clients. The virtual server name and IP address migrate among several physical nodes. In effect, the client connects using the virtual server name without regard to the physical location of the server.
- The third component related to virtual serves, is Server Encapsulation, which is providing transparency of the (application-) services. For the implementation of the Server Encapsulation, three features were added to NT: virtual server naming, named pipe re-mapping (instead of e.g. \\virtual_node\service to \\host\$virtual_node\service) and registry replication.
The Future
The first product s clearly missing some key features to enable the top-level goal of "just plugging in another system", when increased performance is needed. The base design supports larger clusters, but the test and verification effort made it necessary to constrain the initial release to two nodes (which make the cluster more like an online recovery server...).
Next steps will be a global directory service (the "Active Directory" in Windows2000) coupled with a highly dynamic, cluster specific service and the coarse grain load balancing software will provide the directory with the names of the systems to which incoming clients can connect. Truly distributed applications will be supported by exposing a set of cluster-wide communication and transaction services. Changes to the NT networking architecture are in design to enable low latency, high bandwidth cluster interconnects such as Tandem's ServerNet and Digital's MemoryChannel. Further, very high performance shared nothing clusters require some form of I/O shipping, where I/O requests are sent by the cluster communication service to the system physically hosting the disk drive. In general, it can be said that the second phase will focus on scalability and extending availability management. This scaling effort has two major components: 1) there is the cluster software itself, where scalability of the algorithms used in the distributed operation is critical to growing clusters to larger numbers of nodes and 2) there might be an introduction of cluster aware mechanisms for use by developers of sophisticated servers that might exploit cluster-style parallelism. In support of such an approach it would be necessary to provide programming interfaces for cluster membership and communication services, similar to services in Isis. Server developers would then use these to build scalable applications.
However, more recent information is still discussing even more lancunes in the MSCS solution:1
- When will MSCS support more than a two-node fail-over solution?
- What applications are "cluster aware" enabling true seamless fail-over?
- Will NT Server scale effectively?
More information about MSCS can be found on the following pages:
Microsoft's white paper on Clustering
The Design and Architecture of the Microsoft Cluster Service
Microsoft Expands Clustering Capabilities Of Windows NT Server 4.0 Enterprise Edition
Microsoft Cluster Server Update
Clustering with win2k Introduction - Cluster Service - Network Load Balancing - Conclusions and the future - More info
Introduction
The definition of a cluster in the context of win2k: A cluster is a group of independent computers that work together to run a common set of applications and provide the image of a single system to the client and the application.
So, with the introduction of Windows 2000 the definition is somewhat more specific than the traditional definition used with MSCS for NT4. The benefits and features are enlarged, and besides the Cluster Service (CS), another type of clustering has been put on the foreground: Network Load Balancing (NLB). The CS is now capable of managing 4 nodes and mentioned for back-end solutions like databases, ERP or file servers. NLB with maximal 32 nodes, can be used for front-end use: mission-critical TCP/IP-based services Web, Terminal Services and virtual private networking. Both types of clustering are discussed. However, there are more aspects than covered here and some basic knowlede is taken for granted.
Cluster Service
Win2k, and hence clustering options, will come in different flavors. Win2k Advanced Server is capable of supporting 2-node failover, and the Datacenter Server version can have a 4-node failover. Several aspects of win2k-CS and MSCS for NT4 are the same, like the necessity for applications to be cluster-aware, the shared nothing model is maintained and the used definitions (see MSCS for NT4 if you're not familiar with these concepts), but there are extra features in the CS-management tool.
The instrumentation mechanism provided by CS for managing resources are the Resource DLLs, defining resource abstractions, communication interfaces and management operations. Resources are physical or logical entities, which can be grouped into resource groups, like a Virtual Server. Two virtual servers can be grouped into a node (see Figure 2. and 3.). A resource group can be owned by only one node at a time and individual resources within a group must exist on the node that currently owns the group.
Figure 2. Physical view of virtual servers under CS.
Figure 3. Client view of CS virtual servers.
Some changes to the base OS were required to enable the new cluster features, including:
- Support for dynamic creation and deletion of network names and addresses
- Modification of the file system to enable closing open files during disk drive dismounts
- Modifying the I/O subsystem to enable sharing disks and volume sets among multiple nodes
| Component | Functionality |
| Event Processor | Receives event messages from cluster resources and performs miscellaneous services such as delivering signal events to cluster-aware applications |
| Object Manager | A simple object management system for the object collections in the Cluster Service (the same). There are 6 Server Cluster Objects defined: Group, Network, Network Interface, Node, Resource and Resource Type. All of them do have properties, which are the attributes describing the object. |
| Node Manager | Controls the quorum Form and Join process, generates node failure notifications, and manages network and node objects (the same). Implemented via heartbeats and regroup events. |
| Membership Manager | Handles the dynamic cluster membership changes and monitors the health of other nodes within the cluster |
| Global Update Manager | A distributed atomic update service for the volatile global cluster state variables (the same) |
| Database Manager | N/A |
| Checkpoint Manager | Stores the current state of a resource (in general its registry entries) on persistent storage (aka the quorum resource). Applications that are not cluster-aware store info in the local server registry. |
| Log Manager | Provides structured logging to persistent storage (aka the quorum resource) |
| Resource Manager | N/A |
| Failover Manager | Controls the placement of resource groups at cluster nodes. Responds to configuration changes and failure notifications by migrating resource groups (the same) via the node preference list (which also enables a possibility for cascading failover to subsequent servers in the list)(click here if you want to see the failover process flowcharts, or the whole doc.) |
| Network Manager | N/A |
| Communications Manger | Formerly know as Network Manager, and guarantees reliable delivery of intra-cluster messages |
| Configuration Database Manager | Formerly know as Database Manager, and running on each node |
| Event Log Manager | Replicates event log entries from one node to all other nodes in the cluster |
| Resource Monitors | Monitors the health of each cluster resource using callbacks to resource DLLs. They run in a seperate process, and communicate with the CS through RPCs to protect CS from individual failures in cluster resources (something like the component formerly know as Resource Manager). By default, the CS starts only one Resource Monitor to interact with all of the resources hosted by the node. |
The Resource Monitor loads a particular resource DLL into its address space as privileged code running under the system account. Resource DLLs provided in win2k Advanced Server and Datacenter Server have the following additional services: Dfs, DHCP, NNTP, SMTP and WINS (click here for a current list of present available CS resource DLLs).
Other aspects covered within CS:
- The graphical tool Cluster Administrator, which can be running on a node or an external computer.
- A new node status name is introduced: evicted. The node is in this status during a manual operation from the Cluster Administrator.
- There are two failure detection mechanisms: through the heartbeat, detecting node failures via datagram messages, and Resource Monitor and Resource DLLs for detecting resource failures (via LooksAlive and IsAlive queries).
- Check out Compaq's white paper for CS/Resource API types, descriptions and control flow.
Network Load Balancing
The NLB server nodes are called hosts and provide scalability up to 32 servers in a cluster and high availability in case of a failure by repartitioning client traffic within 10 seconds.
Client requests enter the cluster via a switch, this incoming IP traffic is multi- or unicasted by NLB to the multiple copies (called instances) of a TCP/IP service running on each host within a cluster. The requests are processed by each host up to the NLB driver and or discarded or passed on to the network layer. This mechanism appears to be faster than internal rerouting of the requests, (the datagram packets aren't consuming CPU-time excessively), or round robin DNS, which doesn't provide a mechanism for server availability. To achieve performance enhancements regarding the CPU-usage processing the packets, NBL allocates and manages a pool of packet buffers and descriptors that it uses to overlap the actions of TCP/IP and the NDIS driver. See Figure 4.
and the network adapter drivers within the win2k protocol stack.
To distribute incoming requests, NBL uses unicast as the default. NBL reassigns the MAC address, which is the same for all hosts. To insure uniqueness, the MAC address is derived from the cluster's primary IP address (see below), and modifies the source MAC address for outgoing packets. However, when there are excessive incoming requests the unicast-mode can result in a considerable performance degradation. Multicast has an advantage comparing to unicast-mode for limiting switch flooding by manually configuring a virtual LAN within the switch.
The clients are statically distributed among the cluster hosts, which load balance dynamically changes when hosts enter or leave the cluster. In this version, the load balance doesn't change in response to varying server loards.
The cluster is assigned a primary IP address, and within the cluster there's for each host a dedicated IP address for intra-cluster communication. Further, for each server there's a host priority manually set. The host priority value is mentioned for applicationes not configured for load balancing. Applications intended for the load balancing have port rules set instead, and the port with the highes handling priority processes the request (this in case single-host load balancing is configured, which is the default). Multiple-host load balancing, set with one of the 3 client affinity modes, uses client affinity.
Other aspects:
- NLB is capable of running in mixed clusters with NT4.
- NLB can be used to scale applications that manage session state spanning multiple connections, except in occasions that a server or network connection fails. Then a new logon may be required to re-authenticate the client and to reestablish session state.
- The performance impact of NLB can be measured in four areas:
- CPU overhead required for analyzing and filtering the packets
- Response times to clients, which increases with the non-overlapped portion of CPU-overhead (called latency)
- Throughput to clients, which increases with additional client traffic that the cluster can handle prior to saturating the hosts. This can be scaled by e.g. using multiple NLBs and distributing the traffic between them using round robin DNS
- Switch occupancy
Both CS and NLB are certainly improvements comparing with MSCS for NT4. Nevertherless, a 4-node cluster configuration with the win2k Datacenter version shows there's still a long way to go: at the moment of writing, Compaq already has a Beowulf cluster up and running with 450 machines. In other words, the "scaling effort" mentioned in the MSCS NT4 future directions aren't really a huge achievement. However, things are made easier for third parties developing cluster-aware applications. Microsoft mention the following additional key areas for improvement: even larger multi-node cluster configurations, easier installation and simpler, more powerful management. Extended hardware support and simplify the development, installation and support for cluster-aware applications by third party companies. And a tighter integration of the infrastructure and interfaces of all Windows-based clustering technologies to enhance performance, flexibility and manageability.
NLB might be promising, but is in its developing stages: most aspects have to be configured manually, performance tests are done with static pages and even Microsoft itself has several smaller NLBs in use (5 x 6 hosts) for better performance.
More information about win2k clustering can be found on the following pages:
Introducing Windows 2000 Clustering Technologies
Windows 2000 Clustering, the Cluster Server. White Paper from Compaq with failover flowcharts and other pictures.
Windows Clustering Technologies: Cluster Server Architecture. A white paper from Microsoft, and also containing a list for further reading.
Network Load Balancing. Another white paper from Microsoft, with performance graphs, a lexicon and a more info-list.
Netware Cluster Service (CSN) Introduction - Benefits - Architecture - Services - Conclusions/future - More info
Introduction
Novell's traditional definition of clustering: "A cluster is three or more computer systems which are joined by an interconnect and function as a single system." It can include other server operating environments such as Unix and Windows NT, and provides true multi-node clustering by supporting up to eight nodes in a cluster. (The preceeding stages developing the clustering stages are Moab, Park City and Escalante.)
Benefits
- NCS enables network resources to be tied to a cluster rather than individual network servers, aka implementing a Single System Imange (SSI). As the configuration is a single manageable object, the NCS also supports Multi-node distributed failover: when more than one node goes down, the surviving nodes take over. When one node fails, distributed failover allows applications and services to be distributed to multiple surviving servers to prevent overload of any single node.
- The Split Brain Detector (SBD) avoids data corruption during split brain conditions by preventing multiple network servers in a cluster from trying to mount and access the same volume of a failed node. A split brain condition exists when a disruption in LAN communication makes it impossible for normal inter-node communication to take place within the cluster. In this event, certain nodes may become isolated from the others such that the separate nodes think that they are the only surviving nodes. This creates a dangerous situation since all nodes may still have access to the shared data storage system. In this instance, if two separate nodes access the same volume, data corruption could occur. NetWare Cluster Service's SBD can detect and resolve these conditions, ensuring that no data corruption occurs.
- Storage Area Networks are supported in the NCS too. A SAN is a dedicated collection of data storage devices that can be shared by network servers connected via hubs or switches using either fibre channel or the Serial Storage Architecture. See Figure 2.
Figure 2. A Storage Area Network (SAN)
- The Virtual Interface Architecture (VIA) is a proposed interconnect protocol standard developed by Intel, Microsoft, and other technology companies to provide high performance/low overhead point-to-point message passing in clustered systems. The programmatic interface to VIA is called the Virtual Interface Provider Library (VIPL). NCS utilizes extended APIs from the VIPL to communicate cluster events to nodes in the cluster. By supporting the VIPL APIs, NCS leverages third party cluster software development, such as Oracle's Parallel Server (OPS) product. Compaq also supports VIA/VIPL.
Architecture
The NCS consists of two main sections: The NDS Cluster Objects, maintaining information on cluster resources, nodes, volumes, attributes, policies and properties, and Netware Cluster Services NLMs that run on each node in the cluster to make sure that the cluster performs as expected.
Figure 3. Systems Arichitecture
Cluster Services
See Figure 3. for the specific service NLMs that are used on each network server in the cluster. The abbreviations are the following:
- CLSTRIB - The Cluster Configuration Library, providing the interface between NCS and the NDS
- GIPC- Group Membership Protocols, tracking cluster membership changes
- SBD/SBDLIB - Split Brain Detector (Only on clusters that utilize SANs), see above
- CRM - Cluster Resource Manager, acts as an event driven finite state machine tracking the real-time status of all resources running on the cluster
- CMA - Cluster Management Agent, acts as a proxy for ConsoleOne
- TRUSTMIG - NDS file trustee migration, migrates the trustee rights associated with a cluster-enabled volume of a failed node to the surviving node that will remount that volume
- NCPIP - Updated NCP protocol engine, providing automatic client reconnect amongst other things
- CMON - Cluster Monitor Utility, to view the status of the cluster's nodes, is running on each nodes
NetWare Cluster Services provides higher availability of network applications, data, and other resources than competing Intel-based clustering systems. Its automatic resource failover to multiple nodes and transparent reconnect capabilities if nodes fail provides users continual access to network resources without loss of network performance. And by leveraging the power of the industry's leading directory service, network administrators can take advantage of the ease and simplicity of NDS' single-point administration of clustered servers in an NCS environment. NetWare Cluster Services delivers greater scalability, better manageability, and higher availability of clustered network services.
As this product is released recently, there was no additional information about future releases and its improved features.
More information about CSN can be found on the following pages:
NCS White Paper
NCS Features and Benefits
Unix for Server Cluster Single System Image - Management - Conclusions - More info
Defenition: A cluster is made up of a collection of single- or multi-processor computers connected the ServerNet system area network (SAN). The computers in the cluster have a single root file system. The root file system can be serviced by an alternate cluster node should the original node fail. Along with a single root file system, the cluster has multiple operating system kernels that cooperate to present the image of a single system. The NonStop Clusters architecture provides this single system image (SSI), but has no single point of failure. Because of the SSI, library routines and system calls can access resources anywhere on the cluster as though they were local.
Single System Image
NonStop Clusters software links individual nodes so they act and appear as a single system. From the cluster console, you see one operating system with one root directory, as though the console connects to a single system. The single system image (SSI) is created by layering a cluster service over each standard UNIX service that participates in the SSI. The cluster service maintains the standard service call interface for the service, so upper levels of the operating system need not change.

- Node Related Services, like cluster filing environment for consistency in the naming convention within the cluster, cluster membership services, time synchronization and cluster-wide swap service (it's possible to allocate swap space from partitions on other nodes)
- Process Related Services, like cluster-wide process management and migration (or pinning the process), load leveling and system V IPC
- Networking Services, TCP/IP Networking Services, Cluster Virtual IP Address (CVIP)
- Internal use of TCP/IP, within the application
- Parallel server applications, NonStop Clusters allows up to one instance of an application in each node to listen on the same TCP port, the system then distributes the connections amongst the various listeners
- Device related services: Cluster-wide devices and pipes, STREAMS support, console devices in the cluster
- The Event Processing Services monitors event messages as they are added to the system log and searches for specific patterns in the messages, taking a designated action when a pattern match is found. This can be an execute of a script/command or sending a notification message
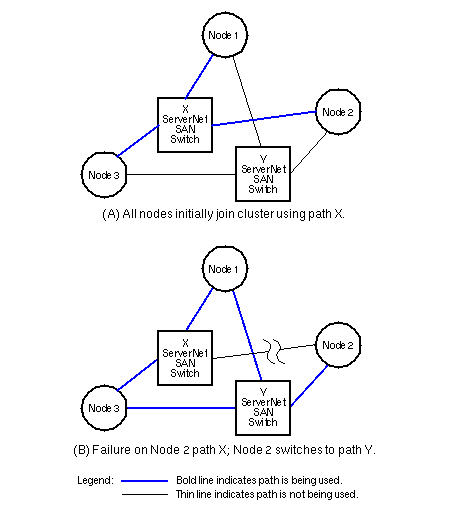
- ServerNet SAN Services, using a Servernet PCI Adapter (SPA), is providing low-level communications services across the SAN: status and error mesasges, offline and online diagnostics.
(click here for more fancy and colorful pictures)
The NonStop Cluster Management Suite (NCMS) provides a GUI to the following system administration applications:
- Configuration Manager: Serves as a specialized editor used to modify the contents of various configuration files. The following types of files can be edited: Insight Manager agent initialization files, (SNMP) agent initialization files, EPS configuration files, and Java property files used to configure operation of the NCMS applications.
- ServerNet SAN Manager: Monitors and controls the cluster ServerNet SAN. Monitoring functions include: state and status of the ServerNet SAN paths and fabrics, various I/O and error/recovery statistics associated with paths and SPAs, and SPA register contents. Control functions are available to designate the paths (X or Y) used between the nodes in the cluster and to reset SPA-related statistics. The ServerNet Manager also displays alert messages when events such as path failures or node removals occur.
- Keepalive Manager: Monitors and controls the processes and daemons registered with the
keepalive daemon. Icons indicate whether a process/daemon is down, has been restarted at least once, or is running and has not required a restart.- Virtual Processes (VPROC): Allows processes to run on any node in the cluster and allows processes to access cluster resources that are physically located on other nodes.
Conclusions
Unix for Server Cluster / NonStop Clusters (Unixware 7) are currently in a beta stadium, (maybe already released by the time you're reading this). There are very small differences in their features, and therefore explained here together. Both solutions take advantages of the Unix OS comparing to e.g. Windows, like the IPC, swap service, mounting, load balancing and application scalability. As both implementations are relatively new, time will tell about its usefulness, and possible improvements.
More information about Unix for Server Cluster can be found on the following pages:
Unixware NonStop Clustering information and the Datasheet
Reliant HA Datasheet and the Technical White Paper
Admin/readme information of the Unix for Server Cluster beta-version CDrom
TurboCluster Server for Linux Introduction - Benefits - Architecture - Future - More info
 Introduction
IntroductionTurboCluster Server works by virtualizing a set of independent server nodes into a single unified service network. This unified network is visible to the outside world as a single virtual IP address and host name. When a client request come into the network, it goes to the Primary TurboCluster Server Advanced Traffic Manager (ATM) node. This node manages the virtual identity and is responsible for binding the loose set of server nodes into a unified service network. Once the ATM receives the request, it determines which of the available servers in the cluster is best able to service that request. It then forwards the client request to that server for proper disposition. When the server has handled the request, and is ready to respond, it the communicates directly back to the client. Because response traffic is typically much havier that request traffic, this can help eliminate the ATM node as a single point bottleneck.
Benefits
- A major difference between TurboCluster and other cluster implemetations is, that the Linux version can be used in a heterogenous environment: it supports Linux, Windows NT and Solaris Cluster nodes. This is implemented with EnlightenDSM software. As the structure of the cluster is modularized, it's easy to scale up the cluster by adding nodes, or clusters within clusters.
- Dynamic load balancing is used when the ATM transfers the client request to one of the cluster server nodes (see introduction). The ATMs themselves are configured with persistent round robin load distribution.
- ATM only forwards traffic that has been pre-authorized, significantly improving network security by acting as a virtual firewall in front of mission critical application servers.
- Implementing the Intermezzo file system: this software facilitates content publication and synchronization among the the various servers. Should one of the servers be offline at the time the data is synchronized, Intermezzo will queue up the outstanding write operations and will then resynchronize the offline node as soon as it is brought back online. By using Intermezzo, new or updated contents will be automatically replicated among the other nodes (when required). Further, Intermezzo is configured to use the private LAN for all the synchronization traffic, thus removing some congestion from the high traffic front-end network.
- Other benefits are the support of non-cluster-aware applications together into a single virtual network, and Web-, GUI- or Console-based administration.
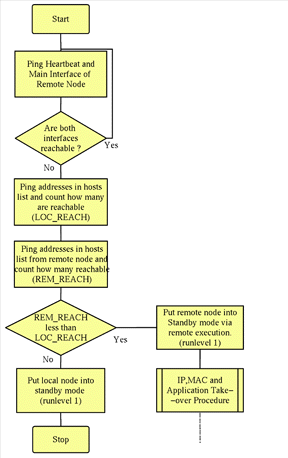
Figure 5. Flow chart showing overview of the cluster deamon algorithm
Architecture
As outlined in the introduction, the client request is first processed by the primary ATM, or in case of high availability within the cluster, (one of) the backup ATM. If an error occurs in in the primary ATM, an election will occur to determine wich of the backup ATMs will be promoted. (See the graphical representation of the architecture.)
To maintain availability, the primary ATM routinely verifies the health of each and every server node within the cluster. This is accompplished through the use of system-level checks and Application Stability Agents (ASA). The ATM first sends an ICMP packet to the node to determine if the system is responsive, it then verifies if the system is responsive. The verification is either through an ASA or through a generic service check (like HTTP, HTTPS, IMAP, POP, SMTP or NNTP), when the ATM will open a connection to the service port and will execute a transaction. When a service doesn't have an agent written for it, the ATM will attempt to open a connection to the service port. Users can write their own ASA if they want to. (see Figure 5 for the algorithm of the heartbeat management)
Future
The benefits of the TurboCluster solution from Linux has a promising future, however there are some aspects not fully exploited by this cluster solution. The following version(s) will incorporate the support for high-end database solutions, as currently some database implementations are possible (like Oracle 8 Enterprise edition). Other mentioned features some customers want to see incorporated in the TurboCluster are the dual Sendmail queuing and delivery for concurrent operation and that the CODA distributed file system for a cluster file system should be evaluated as well.
More information about TurboCluster Server can be found on the following pages:
High performance Linux
User Guide
Example of implementing a cluster with Linux
Technical case study of Turbocluster Server 4.0
1. The question of whether NT is ready for the enterprise largely hinges on the fault tolerance and scalability of NTS and the hardware platform it resides on. Microsoft has long promised these features of enterprise computing to be delivered through Microsoft Cluster Server (MSCS).
- Server Farms Clustering enables you to link separate computers or Nodes to work as a single system. MSCS currently provides a two-node configuration, where if one Node fails the remaining node will pick up the load. Future MSCS clustering solutions will handle up to 16 nodes. The ability of Microsoft to achieve multi-node clusters is really linked to the scalability issue. One of the key features of an effective multi-node cluster would be the ability of the cluster to load balance. Unfortunately Microsoft do not have an application that can achieve this. There are some examples of application developers who have achieved this, for example Citrix's WinFrame load balancing option pack lets you group multiple WinFrame servers in a unified server farm. Similarly Oracle has created versions of its database that scales by enabling four nodes to a cluster.
- Application Support A key component of clustering is the application support. Most generic fail-over solutions today will enable end-users to restart their application on the surviving node. To have true fault tolerance you will require applications that are "Cluster aware". This will enable seamless fail-over to the end-user. There are some examples of independent ISVs developing cluster aware applications. On the whole however ISVs are waiting to see Microsoft lead the way with SQL, Exchange, IIS and other applications. Many are watching SQL Server 7.0 which uses the Online Analytical Processing (OLAP) engine. The OLAP engine can distribute data 'cubes' among many nodes in a cluster. This engine enables query building that assembles data regardless of the 'cubes' location in a cluster.
- Scalability It is Microsoft's practice to build software platforms for commodity hardware. This has not changed with clustering and while large SMP systems will exist (up to 8 way by 2000), the search for scalability and availability will be found by simply adding 4 way CPUs systems to your cluster. Another issue of scalability is the "shared disk" vs "shared nothing". The shared disk clustering approach is where any software on any node can access any disk connected to any node. In the shared nothing clustering approach no direct sharing of disks between nodes occurs. Shared disk strategy is used by Oracle Parallel Server architecture with software to maintain consistency of data on shared disks. Tandem is the leader of the shared nothing strategy, which includes a high speed interconnect software that has been made MSCS aware. Tandem contend that the Shared nothing strategy is best for scalability and have demonstrated a 16 node (each with 4 x 200MHz) and 2TB database scaling on NT.
- In summary there are many initiatives been pursued to bring NT Server in to the enterprise. Whilst it appears that there are no real "commodity" solutions today, most ISVs are porting existing scalable applications to NT, with the view that NT will be the future enterprise platform. If you want a clustered solution today, MSCS provides a two node fail over solution with limited fault tolerant application support (eg: SQL Server)