File Systems
Second Extended File System
|
File Systems (alphabetical order) AFS CIFS CODA Ext2 Introduction Virtual FS Structure Links GFS MS-DOS NFS NTFS Odyssey Samba UNIX Some definitions and general technology |
The second extended filesystem, ext2 is an improvement of the first extended filesystem, which has its origins in the Minix FS. It is basically unix file semantics with some add ons (see structure). The design goals were, naturally, excellent performance (who doesn't?), robustness and had to include provisions for extensions to allow users to benefit from new features without reformatting their file system. Anyway, it is the de-facto standard Linux file system. There's already a pre-version of Ext3, wich has the same features as ext2 + Journaling. This page deals with the VFS, a layer above the ext2 fs and the structure (that section also includes the standard features of the fs).
The Linux kernel contains a Virtual File System layer which is used during system calls acting on files. The VFS is an indirection layer which handles the file oriented system calls and calls the necessary functions in the physical filesystem code to do the I/O. See picture below. The process goes like this: when a process issues a file oriented system call, the kernel calls a function contained in the VFS. This function handles the structure independent manipulations and redirects the call to a function contained in the physical filesystem code, which is responsible for handling the structure dependent operations. Filesystem code uses the buffer cache functions to request I/O on devices.
There are three types of descriptors: a mounted file system descriptor with several pointers (which, among other things, allow the VFS to access the filesystem internal routines), an i-node descriptor (pointers for to act on any file) and an open file descriptor (with pointer for to functions that can act only on open files).
Standard features Support of the standard Unix file types, i.e. the regular data files, directories, links, device- and character special files. The new VFS layer in the kernel has raised the limit of the file system size to 4 TB, it provides long file names (255 characters) and the 5% reserved block for the super user for recovery options. Advanced features meaning, advanced at the time of writing and do not neccessarily have an equivalent in Unix. It is possible to choose the logical block size (1024, 2048 and 4096), it implements fast symbolic links (doesn't use any data block on the FS). Another nice thing is that ext2fs keeps track of the filesystem state by setting the bit to "clean" or "not clean" when a FS is mounted in read-only and read/write mode respectively. This information is storedin a special field in the superblock and used by the kernel to trigger FS checks. To check or not to check is determined by the mount counter, also residing in the superblock. The counter is incremented each time an FS is mounted, at the max value the the FS checker forces the check (before that you can skip the voluntary FS checks). With the program tune2fs you're able to set several of those parameters. Two new file types has been added: immutable files (can only be read) and append-only files (can be only opened in write mode, but the new content is always added at the end of the file). The intention is to protect sensitive configuration files and growing log files. Physical structure The physical structure of Ext2 filesystems has been strongly influenced by the layout of the BSD filesystem (McKusick et al. 1984). A filesystem is made up of block groups. Block groups are analogous to BSD FFS's cylinder groups. However, block groups are not tied to the physical layout of the blocks on the disk, since modern drives tend to be optimized for sequential access and hide their physical geometry to the operating system via the device drivers and/or and array controller. See the MS-DOS structure for an interesting comparison with the ext2 layout.
Each block group contains a redundant copy of crucial filesystem
control informations (the superblock (always 1024 bytes) and filesystem descriptors) and
also contains a part of the filesystem: a block bitmap, an i-node
bitmap, a piece of the i-node table, and data blocks).
Directories are managed as linked lists of variable length entries containing the i-node number, entry length, file name and its length. In this way it's possible to support the long file names without wasting disk space. Performance The optimizations include buffer cache management by performing readaheads, not only on files but also on directory reads (explicit by readdir calls or implicit by namei kernel directory lookups). Secondly, the ext2 FS contains allocation optimizations: block groups are used to cluster together related i-nodes and data: the kernel code always tries to allocate data blocks for a file in the same group as its i-node. This is intended to reduce the disk head seeks made when the kernel reads an i-node and its data blocks. Related to this is the preallocaiton mechanism. Ext2fs preallocates up to 8 adjacent blocks when allocating a new block for writes. Preallocation hit rates are around 75% even on very full filesystems. It also allows contiguous blocks to be allocated to files, thus it speeds up the future sequential reads. |
 back to
back to 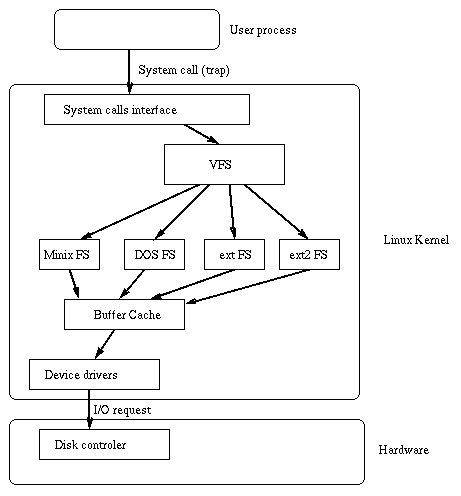
References and/or more information
Design and Implementation of the Second Extended Filesystem
John's spec of the second extended filesystem
Extended filesystems (Ext, Ext2, Ext3)