File Systems
(alphabetical order)
AFS
CIFS
CODA
Ext2
GFS
MS-DOS
NFS
NTFS
Components
NTFS v1.1
NTFS v5.0
How
Links
Odyssey
Samba
UNIX
Some definitions and general technology
|
The New Technology File System: NTFS
NTFS v1.1 is the filesystem of the system Windows NT®, and is also described as NTFS v4.0. See below for the additions that make it to NTFS 5 (in Windows 2000). It supports almost all POSIX features, all HFS features, and all HPFS features. It has some aspects that may be called advantages if you like:
- It can deal with large capacity (up to 2^46 GB) storage units.
- It has built-in data compression: this is implemented at a file attribute level, which means that you won't loose a lot of data if a corruption occurs. It is although only used at a file level. Data become compressed by being "stuffed" into the free spaces within clusters. So, if you have 512 bytes of information in a 4 KB cluster (it only works on a partition with 4 KB clusters), the unused portion of that cluster can be utilized as compressed space.
- It uses a log file for transactions: it logs the atomic action, which is a set of operations that is not allowed to be devided. It is a mechanism to maintain data consistency.
- It supports a 16-bit Unicode character set (opposed to 8-bit ASCII). This provides flexibility: data in this code is much more portable to the non-Latin alphabet languages.
 back to IT stuff back to IT stuff
The building blocks of the NTFS
NTFS 1.1/4.0
The Master File Table, MFT
In NTFS, everything is a file. All metadata are stored in system files. It is quite unusual for a filesystem, but it allows the filesystem driver to manipulate these data in a generic way (for example, to perform access control on them), and since these data can be moved and located anywhere on the storage unit, it reduces the risk of damage. The Master File Table (MFT) is the most important system file. It contains information about all the files of the volume. There is one MFT per volume.
Layout of the MFT:
The MFT is a sequence of FILE records. The first 16 FILE records describe system files, as follows:
| FILE record number |
File name |
| 0 |
$MFT This "Master File Table" is the head librarian of sorts for all of the files (including metadata) and directories in the partition. In that sense it's very close to the original File Allocation Table. The MFT manages the other metadata files, by dividing the table into numerous records. These records contain information for all of the files and directories - where they exist on the drive, associated permission levels, attributes, etc. |
| 1 |
$MFTMirr. This is a system file that duplicates the first 16 records of the MFT (critical data) for recovery purpose. This is stored in the middle of the disk. The $MFTMIRR file allows greater data read success by offering this copy of the MFT records in case the active MFT (typically at the beginning of the disk) is somehow corrupted. Therefore, if the beginning of the disk where the actual MFT lives encounters corruption, the show can go on while the file system takes complementary action (like updating $BADCLUS, etc.) in order to avoid performance degradation and possible data loss in the future. |
| 2 |
$LogFile |
| 3 |
$Volume, conains info about the volume. |
| 4 |
$AttrDef, info about all file attribures usable in a volume |
| 5 |
. (root directory) |
| 6 |
$Bitmap, that indicates which LCNs [=logical cluster number] of the volume are used. |
| 7 |
$Boot, see the layout. |
| 8 |
$BadClus. As soon as a read error occurs due to a physical error on the disk, the file system reacts by remapping the afflicted data to new drive coordinates and updates the $BADCLUS metadata file with the location of the faulty cluster(s) |
| 9 |
$Quota. Only contains quota info in Winwows 2000 |
| A |
$UpCase. Contains an Unicode upper case translation table. Is it used to perform file name comparison (to sort a directory, or to search for a file). |
| B |
B to F are reserved for extension FILE records of the MFT itself (they are not for future use). |
| C |
| D |
| E |
| F |
| 10 and higer |
Any file |
NTFS-specific Attributes (primarily maintained by the MFT) store vital information about all of the files and directories. Don't get these attributes confused with what you might normally think of as attributes, mainly the old read-only, hidden, system, and archive attributes.
| Attribute Name |
Brief Description |
| $VOLUME_VERSION |
Volume Version |
| $VOLUME_NAME |
Disk's Volume Name |
| $VOLUME_INFORMATION |
NTFS Version, and Dirty Flag |
| $FILE_NAME |
File of Directory Name |
| $STANDARD_INFORMATION |
Hidden, System, and Read-Only Flags, as well as file time stamps |
| $SECURITY_DESCRIPTOR |
Security Information |
| $DATA |
File Data |
| $INDEX_ROOT |
Directory Content |
| $INDEX_ALLOCATION |
More Directory Content |
| $BITMAP |
Mapping of Directory Content |
| $ATTRIBUTE_LIST |
Describe(s) Non-Resident Attribute Header(s) |
| $SYMBOLIC_LINK |
Virtual Data Linkages. Not implemented in NT4, but used in Unix; in Windows 2000 the sym link is called reparse point |
| $EA_INFORMATION |
OS/2 Compatibility Attribute Extensions |
| $EA |
OS/2 Compatibility Attribute Extensions |
NTFS 5
Some components of the NTFS v1.1 were changed, and new features were added to get the NTFS v5.0. This paragraph offers you a summary of the main "features" involved.
Quota. The first able on this page already mentioned it: the NTFS5 in win2k does support quota (essential quota information is stored in the metafile $QUOTA) . it is possible to set quotas on a "per user" or "per volume" basis, in quota-mode monitoring, enforce, or off. This means that users cannot subvert the OS to breach their respectively defined size limitations, assuming that the hosting NTFS volume stay sufficiently corruption-free.
Security. More NTFS security granularity. Under NT4, granularity in assigning access to users and groups to objects in a filesystem was extremely weak. This shortcoming was spearheaded with the release of NTFS 5.0, introducing flexibility in determining how much access you want to assign to whom: control now exists with how security changes are or are not propagated down a filesystem. IMHO, the idea very much looks like the one used for file permissions in NetWare, where NetWare has the additional advantage with the button "calculate the effective user rights", saves time.
Encryption. The Encrypting File System (EFS) sounds like a part of the file system, but it isn't. It sits on top of NTFS so to speak, and uses file flags which indicate to the filesystem driver the need for crypt-action, it's not even truly a feature within NTFS 5.0. Technically-speaking, it's a privileged system service (also a run-time library, and driver) that runs securely in kernel-mode and is tightly connected to the file system driver, and runs "behind the scenes," interacting with the filesystem on a need-be basis. Therefore, a user cannot access the filesystem without going through EFS (see the MS website for the white paper).
Distributed Link Tracking. DLT basically monitors all kinds of links in your system, be they shortcuts, OLE links, etc., for changes in name and/or directory path alterations. Running as a system service in the background, DLT attempts to prevent any broken links from causing you grief. It even works on the network. This means that a client application can continue to access a linked spreadsheet or database, even if the spreadsheet or database location has changed.
DLT claims to be able to resolve broken links in any of the following scenarios (including combinations of any of them): 1) altered Windows 2000 computer name, but still in same domain; 2) altered name of network share housing the link; 3) data moved from one NTFS 5.0 volume to another (within the same machine or even to another machine in same domain); 4) disk(s) logically or physically moved to another machine in same domain.
Dynamic Volume Management (see also DVM, Solution Spotlight). The Dynamic Volumes reside on Dynamic Disks, with which you are no longer restricted to four volumes per disk; they can consist of just a portion of a physical disk, an entire disk, or span multiple disks. Features: 1) Fewer reboots. you can often add disks and create, extend, or mirror a volume without rebooting, letting users work without interruption and saving administrators' time; 2) Self-describing disks. Win2k stores disk configuration metadata for dynamic volumes on each disk. Self-identification of managed disks ensures that disk controller and other disk reconfigurations or cluster disk ownership transfers are error-free. ADD MORE INFO !!!!
NTFS Change Journal.
The Windows 2000 Server volume-wide Change Journal (or Change Log) tracks modifications to NTFS 5 files over time and across system reboots. As files, directories, and other NTFS objects are added, deleted, or modified, NTFS enters records into the Change Journal, one record for each volume on the computer. Each record indicates the type of change (read, write, move, and so on) and the object that was changed. Independent software vendor (ISV) developers of system-level applications (such as file system indexing engines, content replication engines, and storage archiving and migration applications) can make use of the Change Journal: Applications that periodically scan the file system for changes can now, use the Change Journal instead of scanning the entire file system. For large volumes, this can reduce the time for scan operations from hours to seconds. For example, a backup application can consult the Change Journal to build its list of files before performing an incremental backup.
Reparse Points are like the symbolic links used in UNIX, but it is not the exact same thing. It's more of an infrastructure item that allows the use of mount and junction points from both the microscopic machine POV, and the network-wide POV. In coding terms, think of a reparse point as a hook of sorts, which introduces extended functionality into NTFS and the storage subsystem. Now Win2k, and apps for Win2k, can call to reparse points, which can in turn receive said call, and before returning info regarding the storage subsystem can perform/execute operations that directly effect what info goes back to the source of the operation call. These "operations" are the fundamental basis for the mount and junction point techs mentioned above.
- Mount points are a cousin to junction points (see below): a mount point serves to allow the root of a volume to me mapped (NT term) or mounted (UNIX term) to a directory on another volume. Mount points allow for more flexibility in adding new drive space to an already configured OS and set of apps. Say for instance, you install AppX to C:\AppX and C:\ has run out of disk space due in part to AppX's large & growing disk needs. A mount point using another new volume with space available to C:\AppX is your easy salvation.
- Junction points on the other hand, allow for configuring one directory to point to a second directory, on any volume on the same machine. This is handy when you want to deem a directory common per se, and make it available to X number of users via their user directories for instance. The catch: junction points (which represent directory junctions) only work on the same machine ... DFS on the other hand comes in to play when you want to expand this functionality past one machine, allowing the junctioning of multiple directories from multiple machines to one single directory, or share most likely. (So, you could offer up a super MP3 server as \\ServerName\MP3 on a network, even though that share consists on multiple directories, volumes, and machines.)
back to IT stuff
How does it work?
Knowing what components are involved is one thing, understanding what they do, and how they do it, is something else.
It is possible to network the NT and Win2k machines, but the file systems are very loosely connected,. A step towards a really networked file system is the Distributed file system, which will be discussed in this paragraph.
Distributed File System , DFS.
The features mentioned in the previous section will be used to it's best advantage when the DFS is installed...Here a copy-and-paste of the MS site :
The Windows 2000 distributed file system (Dfs) makes it easier to manage and access files that are physically distributed on servers across a network. Dfs, which is organized as a logical tree structure independent of the physical resource, gives users a view of what looks like a unified hierarchical file system. This eliminates the need for users to remember and specify the actual location of files in order to access them. You have a choice of two Dfs implementations with Windows 2000 Server: stand-alone and domain-based. Both implementations let users take advantage of the unified logical namespace. The domain-based implementation requiresand benefits fromActive Directory. Domain-based Dfs ensures that users retain access to their files in two ways:
-
Windows 2000 automatically publishes the Dfs topology to Active DirectoryTM. This ensures that the Dfs topology is always visible to users on all servers in the domain.
- To ensure that users have uninterrupted access to data, administrators can create Dfs root replicas (two or more copies of the Dfs root, each on a different server) or Dfs link replicas (two or more copies of a Dfs shared folder, each again on a different server). This gives users continued access to their files even if one of the servers on which those files reside is unavailable. The fact that more than one copy exists is transparent to users.
Basic functionality
But this describes what it is supposed to do, not how it actually does these things. Even the white paper couldn't answer all my questions (on the contrary, it raised even more Qs). I tried to summarize the paper, but I couldn't resist adding my onw comments.
First of all, a graphical representation fo the architecture (well, it was called the "various binary components"....)

Figure 1. Block architecture with various components involved in DFS.
| Dfs binary component |
Description |
| DfsAdmin.exe |
Administrative UI tool |
| DfsSrv.exe |
Dfs Server-side service (manages the Partition Knowledge Table) |
| DfsUI.dll |
Calls used by DfsAdmin |
| Dfs.sys |
Dfs driver used by the Dfs Service (for example, to hand out referrals) |
| DfsInit.exe |
Boot time to initialize Dfs (Server only) |
| DfsSetup.dll |
Network Control Panel (also used at install time) |
The DFS proves name transparency to a certain extend; from the clients view. Instead of using the mapped drive letter with an UNC, a single UNC like \\Server_Name\DFS_Share_Name\Path\File is sufficient. The process when a client requests a file residing on a server somewhere on the network goes like this:
1. After the desicion that the requested file isn't stored locally, the client request asks the Partition Knowledge Table (PKT) of the client machine. The PKT maps the logical DFS name space into physical referrals (see Figure 2.).
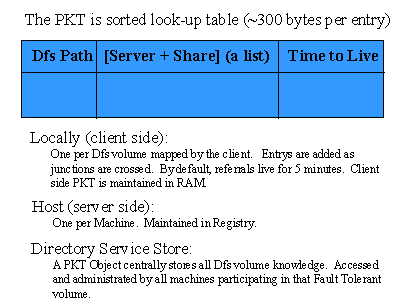
Figure 2. The Partition Knowledge Table, PKT
There's a PKT in every server within the DFS. Are they created locally, or distributed and (re)synchronised via the DFS root? What happens if one gets corrupted? is it updated after failing to try to resolve a clients request, or does it perform a self check? The APIs included in the wp don't state anything about automatic updates, but I can't imagine that everything in configuring and maintaining the DFS is performed manually.
Resolving the logical name into a physical addess is achieve with the DFS-aware redirector (SMB Server) and the DFS driver. There are two new transaction SMBs defined for this, seven public administrative APIs, and 10 private APIs.
2. If the referral cannot be resolved, the client contacts the DFS root.
3. If the referral still cannot be resolved, an error occurs. If the referral is properly resolved, the client adds the referral to its local table of entries. When a DFS client obtains a referral from the PKT, that referral is cached for five minutes. If the client reuses that referral, the time-to-live is renewed; otherwise, the cache expires. If alternate volumes exist for a particular referral, all alternates are handed to and cached by the client. The client randomly selects which referral to use (in the directory-enabled version of DFS, this is based on sites to ensure that clients select available alternates within their site). Btw, DFS makes no attempt to ensure that the data stored between the two shares is replicated.
Especially the third step is interesting, the alternate paths, duplicated files for the sake of load balancing and fault tolerance. This can cause major inconsistencies when the user has write access to the file. The white paper doesn't mention existence of any algorithm solving this type of problem. No, it just advises you to configure this "preferrably only with files having read-access for all users". Yeah, right! What if the sys admin wasn't careful enough, and one or more clients do change the "same" (aka the original or the duplicate) file? Is there a mechanism solving the discrepancies? How and when will DFS know about that? And even if it detects this troublesome situation, which file will be "the correct one" and survive? The file changed most recently, or the original but not the duplicate?
Further, the fault tolerance depend on the type of situation prior to the fail condition: "The speed and implications of the fail-over are dependent on what the client was doing at the time of the failure and how the failure occurred." Uhhhh, isn't it the intention of a true fault-tolerant system that the problems at the back-end shouldn't make any difference for the users view? The wp describes 4 scenarios. The first 2 describe the situation that a client requests a file on a volume of a server that can't answer the request for whatever reason (hardware defect) or when the client does have an open file and the server with the volume fails. To fail-over in the first case, "the client must first detect that the hosting computer is no longer present. How long this takes depends on which protocol the client is using. Many protocols account for slow and loosely connected WAN links, and therefore may have retry counts of up to two minutes before the protocol itself times out." But once it finally realizes that the particular server, DFS immediately selects an alternate server (if non available, the DFS root is queried for possible changes in the server PKT). In the second case the same failover process occurs, but the application that previously had file locks from the previous alternate must detect the change and establish new locks. And may I know how? The local application notices the failure? If the client has an open file to read, does it notice the failure when it send the request to close the file, or is there some regular polling involved from the client application to the server? I.e. e.g. MS Word sending keepalive messages? So the client also stores some session information somewhere? Well, some type of session semantics is needed with cleaning up and re-establishing locks on files.
The two other scenarios are as follows: "A client is browsing an alternate volume (or has open files). The computer hosting the alternate loses a hard disk hosting the alternate, or the share is deactivated. In this situation, the server hosting the alternate is still responding to the client request; the fail-over to a fresh alternate is nearly instantaneous." What about a threshold time before the server decides to use the alternate location? In addition to that, the situation with the open files has an extra requirement: "the application that previously had file handles from the previous alternate must detect the change and establish new handles." HOW?!?! (See also the previous section for comments)
The provided DFS Prgramming Interfaces doesn't deal with fialover conditions (and at the moment of writing I don't have the SDK)
Security within DFS
Dfs allows special handling of security issues at session setup and with ACLs that are not consistent system-wide. ACLs are administerd at each individual physical share.
This may result in conflicting user/group rights, but there are some plausible reasons for their decision:
- A centrally administrated logical ACL database could be bypassed, as users could Net Use directly to the physical resource.
- The logical Dfs volume can cross between FAT and NTFS volumes, as well as contain leaves from other network operating systems. There is no reasonable way to set an inherited Deny ACL which starts on an NTFS volume, passes to FAT, passes back to NTFS, and concludes on a NetWare volume.
- A tool that walks the logical name space, setting ACLs appropriately, would require a complicated message and transactioning engine to ensure that ACLs were queued and updated over loosely connected and/or unreliable networks.
- Storage quotas available in Windows 2000 require an additional burden of tallying storage for all possible users across all possible volumes to establish when users have exceeded their storage allotment.
The DFS-aware client establishes a session setup with the server (on the other side of the junction), which will be cached. The credentials that the user originally supplied (with the request) to connect with DFS are used. If the user did not supply credentials, the credentials cached when the user logged into his or her workstation are used.
But I'd still like to know what will happen if the ACLs are not the same when in case of a replica file accessed via an alternate path. The path is chosen random, so would this mean that sometimes you do have other rights? Does the system realize there's something conflicting going on, and maybe prohibit you from doing anything with the particular file/share? Or should I assume everything is going to be just fine?
Other
Last but not least a few positive remarks. DFS itself is always hosted on a NT or Win2K Server, either in FAT or NTFS format; but when junctions are crossed you can change from one file system to another (even to a volume that resides on a NetWare server). Further, with DFS a volume can be built to encompass all storage on the network, which allows a backup through a single name space (provided that your backup solution is DFS aware).
Implementing DFS using Win2k offers the advantage of integration with the Active Directory Service. This in turn offer the following features:
- Directory services for storing existing administrative information.
- LDAP as the protocol for updating and querying for DFS information.
- Directory services store for providing root-level fault tolerance in DFS.
- Directory services for keeping all participating computers in any DFS root synchronized in their perception of the DFS structure.
- Directory services site topology for providing intelligent replica selection.
- Content Replication Service for keeping alternate volumes synchronized with one another.
Conclusions
Although the current version of the DFS is far from the ideal transparency that a true NOS ought to provide, it is more than just a couple of connected machines with a Microsoft OS installed on it. It starts to provide something that looks like if the distributed volumes can be connected in a hierarchical way (well, at least the overall view of it).
However, there are still loose ends that need to get attention: alternate volumes, file/volume security, the PKT.
|